About Me

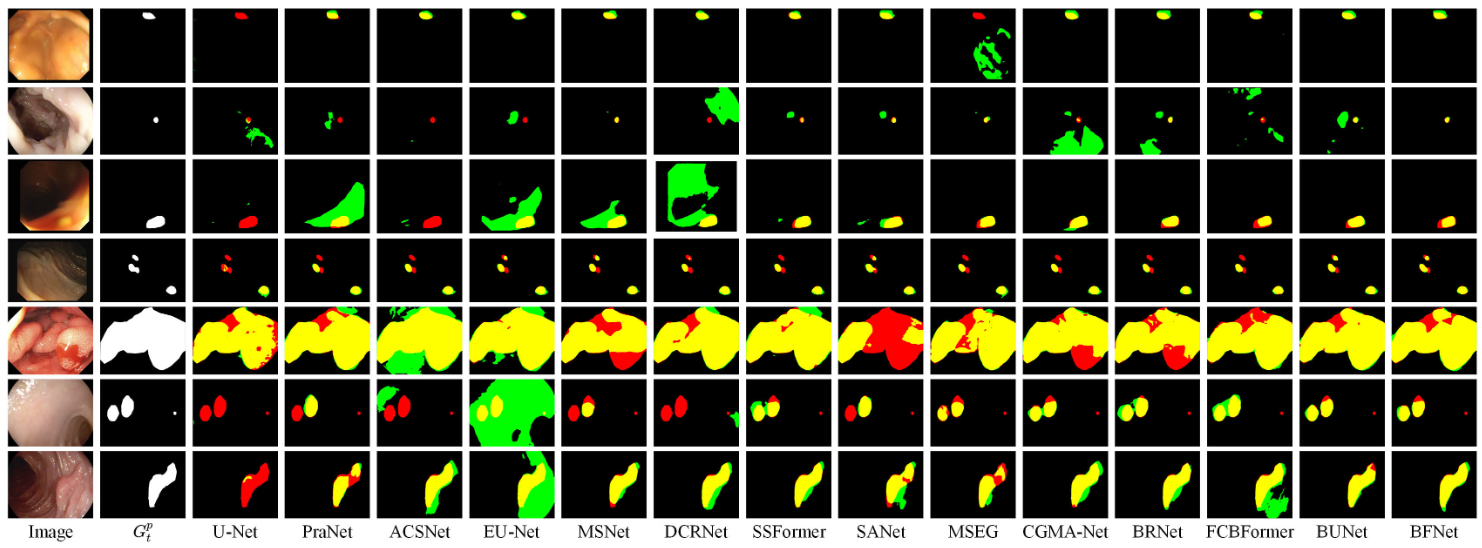
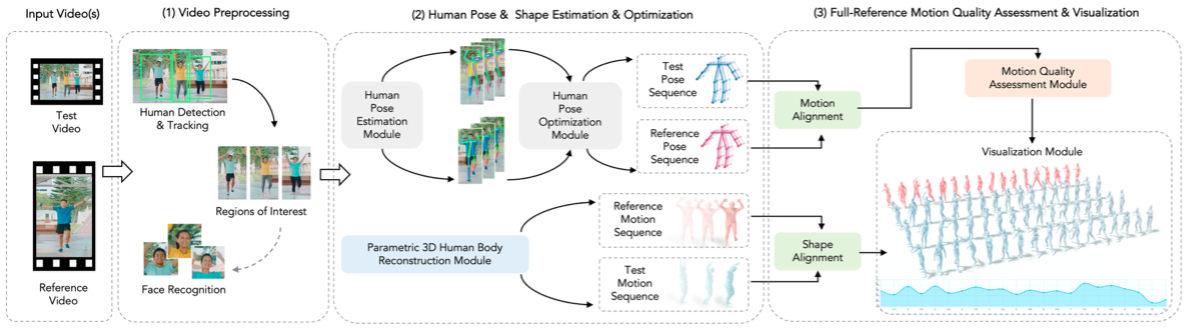
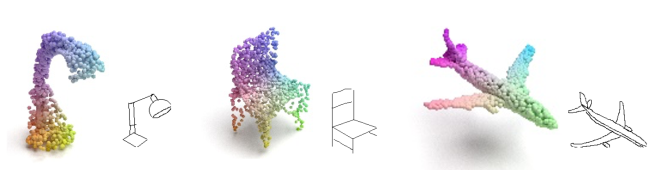
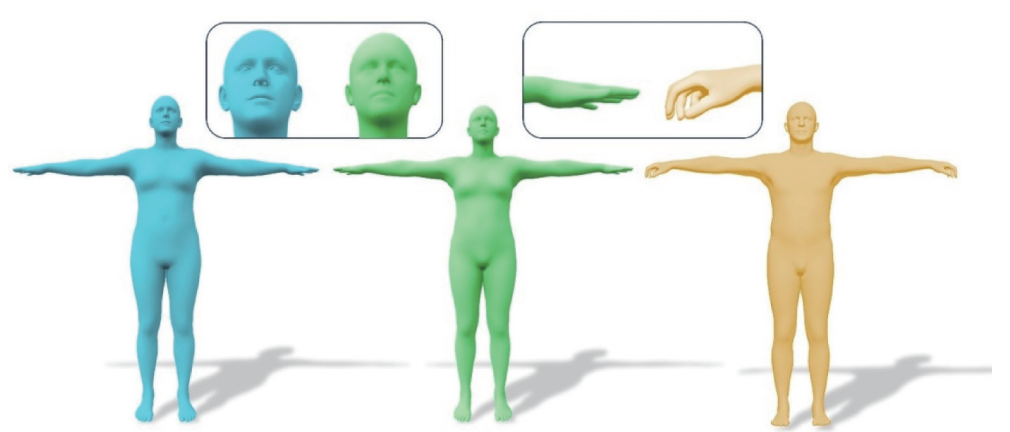
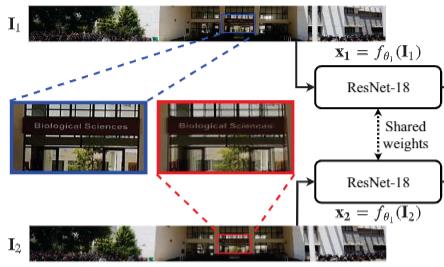
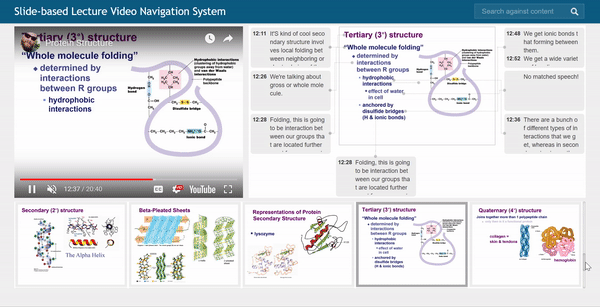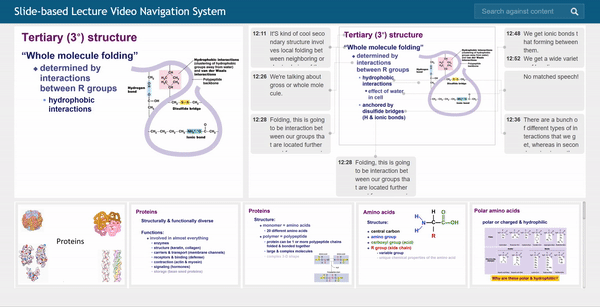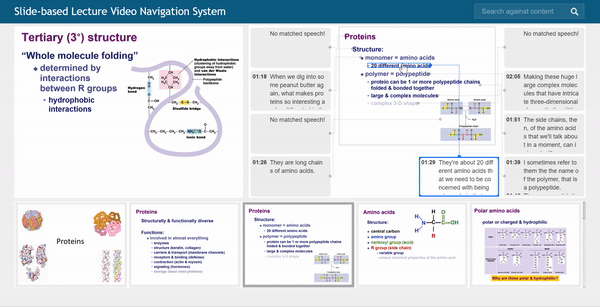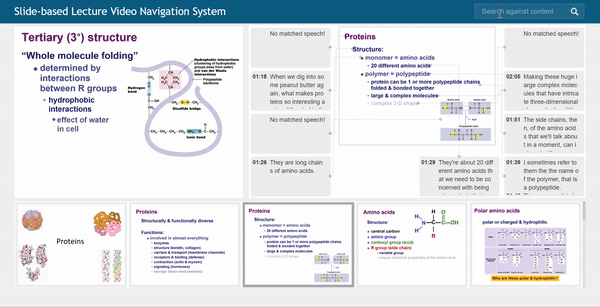
Baoquan Zhao (赵宝全) is currently an associate professor at the School of Artificial Intelligent, Sun Yat-sen University, China. Prior to his current position, he was a Research Fellow under the supervision of Prof. Weisi Lin at the School of Computer Science and Engineering (SCSE), Nanyang Technological University, Singapore, from Sep. 2018 to Jan. 2022. He received his Ph.D. degree in computer science from Sun Yat-sen University, Guangzhou, China, in 2017. His research interests span AIGC, AI Agents, computer graphics, computer vision, and multimedia systems and applications. In these areas, he has published over 60 papers in leading international journals and conferences, and filed approximately 20 Chinese and PCT patents. He has led and participated in numerous national and provincial research programs, including projects funded by the National Natural Science Foundation of China, the Ministry of Science and Technology Key R&D Program, and the Guangdong Provincial Natural Science Foundation. He has long served as a reviewer for prestigious journals including IEEE Transactions on Image Processing, IEEE Transactions on Multimedia, Information Sciences, Pattern Recognition, and Neurocomputing, as well as a Technical Program Committee member for top-tier conferences such as CVPR, ECCV, AAAI, ACM MM, and WWW.
Sun Yat-sen University (Zhuhai Campus), No. 2 Daxue Road, Xiangzhou District, Zhuhai, Guangdong, China, 519082